
Cuando se habla de inteligencia artificial, se comienza por una serie de herramientas y resultados, por norma general, la gestión documental en la inteligencia artificial, es el principio de todo.
Los datos no se transmiten en cazuelas, si no en documentos (paquetes de información, para que nos entendamos). Una buena definición de documento sería la siguiente: «Cualquier conjunto de información que conforme una unidad significativa independiente, registrada en un soporte electrónico, constituye también un documento.»
Inteligencia Artificial
Es un sistema para el análisis de datos que podría identificar patrones y que tomaría decisiones analíticas, como un analista humano usaría su conocimiento y entrenamiento experto, hace algo inteligente.
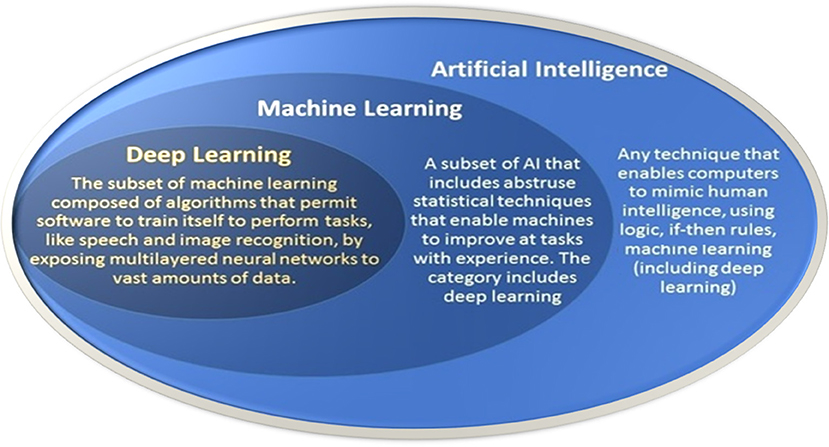
La diferencación entre sistemas de Machine Learning o Deep Learning está relacionada con la capacidad, mientras el Machine Learning es un sistema que mediante la experiencia (analiza datos de un modelo, los evalúa y crea un modelo óptimo), permite a un sistema aprender a reconocer patrones por sí mismo y hacer predicciones.
En 2016 Google inició un proyecto en Google Open Source: Quick, Draw! Dataset, se recogieron aproximadamente, 50 millones de dibujos de 15 millones de personas de diferentes paises para utilizar como base de un proyecto para el reconocimiento de imágenes.

Me tranquiliza pensar que no soy la única torpe con los dibujos, ya hice un curso con Myriam Artola, y voy a ir a por el segundo. Se supone que son unas tijeras, todavía estamos discutiendo si darle al flag as inappropriate… La imagen nos sirve para explicar lo diferente que puede ser una cosa, imagináos una mesa, las hay de 3, patas, de 4, sin patas (adosadas a una pared)… y la cosa es tener imágenes para enseñarle a la máquina a meter todas en el mismo grupo, las mesas.
El Deep Learning utiliza técnicas de machine learning para resolver problemas, imitando la capacidad humana de toma de decisiones. Es muy costoso por la gran cantidad de información que hace falta para entrenar el sistema, para abaratar este coste se suelen usar lo que se llaman transferencias de aprendizaje.
La gestión documental en un sistema de Machine Learning para el reconocimiento y clasificación de imágenes.
Entrenar un sistema de Machine Learning para que reconozca imágenes implica, alimentar una base de datos con imágenes que sirvan para que el sistema aprenda a reconocerlas.
¿Cómo reconoce las imágenes?
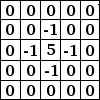
Cuando recibe la imagen crea un mapa de pixeles, en los que se ve la diferencia de color, rango tonal, profundidad de bits, resolución y crea una matriz. En esta imagen vamos a ver la representación original y su matriz.

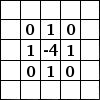
Utilizamos un sistema de convolución para que devuelva una imagen de los bordes y que se puedan identificar objetos en la fotografía. Devuelve una especie de negativo. Lee la diferencia entre los píxeles para crear esta imagen. Quedaría aproximadamente así:

¿Qué necesita para hacerlo?
Esto solo ocurriría si el rango tonal de la imagen es lo suficientemente alto, esto quiere decir que si la diferencia tonal entre pixeles no es la suficiente, la máquina no va a leer la diferencia y no va a poder dibujar el borde de esa cosa. ¿qué tiene que ver esto con la gestión documental?
1º Si esa imagen va a provenir de la digitalización de material analógico, el proyecto de digitalización deberia contemplar un rango tonal lo suficientemente alto.
2º Si la imagen proviene de imágenes digitales, el sistema de validación debería incluir el parámetro rango tonal para aceptar o no la imagen en la base de datos.
Aunque la imagen no se vaya a usar para Machine learning, si la vas a usar en RRSS o publicaciones on line, este requisito, lo vas a seguir necesitando, puesto que la imágenes de lo que se cuelga on line son indexadas por motores de búsqueda que utilizan sistemas de Inteligencia Artificial para etiquetarlas. Si no pueden hacerlo por el rango tonal bajo, vas a perder visibilidad, encontrabilidad. A Google le gusta lo que reconoce y lo premia enseñándolo más.
Es muy común en procesos de digitalización de imágenes que la calidad de las mismas no valga para este tipo de bases de datos, sobre todo en proyectos antiguos, en los que se usaban escáneres sin posibilidad de configuración manual.
La preingesta y la documentalista.
La fase en la que hace falta una persona documentalista en un proceso de IA, es la de seleccionar y aportar los estándares necesarios para el proyecto. Seleccionar los datos y documentos con la información necesaria.
Definir qué tipo de datos, el formato, las calidades… Un buen comienzo son las ISO, determinar qué ISO se pueden usar en ese proyecto. Por ejemplo, para digitalizar material de Patrimonio cultural tendríamos la ISO/TS 19264-1:2017, las recomendaciones de Fadgi, etc.
Si quieres saber más, piensas que te hace falta una consultoría para tu proyecto o crees que algo no funciona en tu sistema, contáctanos, seguro que podemos ayudarte.
BIBLIOGRAFÍA